Относительно недавно встала передо мной задача переместить файловое хранилище объемом 90 ТБ на объектное хранилище S3.
Из сложностей было то, что в рунете почти нет статей на тему миграции, а те, что есть, описывают подключение внешнего хранилища.
Мне же нужно было,чтобы S3 было именно в качестве основного хранилища.
Задача не особо сложная, но требует предельной внимательности в процессе переноса.
Предварительные условия
Nextcloud 27 версии или выше. На версиях ниже 27 версии некорректно работает MultiPart Upload, вследствие чего файл загружается, но Nextcloud не воспринимает заголовок Content-Length и в БД файл оказывается нулевого размера, а такие файлы Nextcloud даже не пытается вычитать с файлового хранилища.
СУБД: PostgreSQL. Можно и MySQL, но на маленьких объемах, в противном случае диск с БД постоянно будет забит IO, плюс на MySQL сложнее реализовать Point-In-Time Recovery, а для S3 в качестве основного хранилища это критично, так как в случае потери БД нельзя будет выполнить occ rescan, он на S3 не работает.
Далее описан весь процесс миграции. Все действия выполняются на свой страх и риск.
Выгрузка списка файлов, хранящихся на локальном хранилище
datadirectory = Директория NextCloud, в которой располагаются все загруженные файлы.
dbname = Имя базы NextCloud.
Следующей командой выгружается список пользовательских файлов
psql -qt -d {{ dbname }} -U $dbUser -c "select concat('urn:oid:', fileid, ' ', '{{ datadirectory }}', substring(id from 7), '/', path) from oc_filecache join oc_storages on storage = numeric_id where id like 'home::%' order by id;" > userdata.txtЭтой командой выгружается список метаданных (превью, аватары)
psql -qt -d {{ dbname }} -U $dbUser -c "select concat('urn:oid:', fileid, ' ', substring(id from 8), path) from oc_filecache join oc_storages on storage = numeric_id where id like 'local::%' order by id;" > metadata.txtЕсли сервер БД находится на другой машине, то необходимо указать адрес сервера БД с помощью параметра -h dbHost.
Создание симлинков на файлы и метаданные
Создаем отдельную директорию и в ней запускаем скрипт, который делает симлинки на всех файлы и метаданные. Переменная path указывает на директорию, где хранятся файлы userdata.txt и metadata.txt.
#!/bin/bash
while read target source ; do
if [ -f "$source" ] ; then
ln -s "$source" "$target"
fi
done < $path/userdata.txt
while read target source ; do
if [ -f "$source" ] ;
then
ln -s "$source" "$target"
fi
done < $path/metadata.txtДанный скрипт создаст в директории симлинки вида urn:oid:999. NextCloud сохраняет файлы в S3 именно в таком виде. Симлинки нужны для того, чтобы не копировать все файлы в отдельную директорию и соответственно, сэкономить место на диске.
Синхронизация содержимого директории с S3
Устанавливаем awscli командой apt install awscli.
В Debian и Ubuntu присутствует в репозиториях.
Конфигурируем aws командой aws configure.
При конфигурировании будут запрошены access_key и secret_key к S3.
Поскольку по дефолту aws обращается к серверам Amazon, и не воспринимает endpoint-url в конфигурационном файле, то необходимо сделать алиас в .bashrc.
Параметр —no-verify-ssl нужен, если у вас самоподписанный сертификат или невалидная цепочка сертификатов.
alias aws=’aws —endpoint-url https://s3Endpoint —no-verify-ssl’
Команду, соответственно, запускать из той директории, в которой у нас лежат симлинки.
aws s3 sync . s3://bucket-name
Вместо bucket-name указываем название вашего bucket.
После синхронизации можно глянуть содержимое командой aws s3 ls s3://bucket-name
Замена путей в БД
До этого все шаги были безопасны, а на этой стадии есть риск реально сломать все.
Необходимо сделать бэкап БД
У всех файлов в БД прописан ID хранилища — это столбец Stor
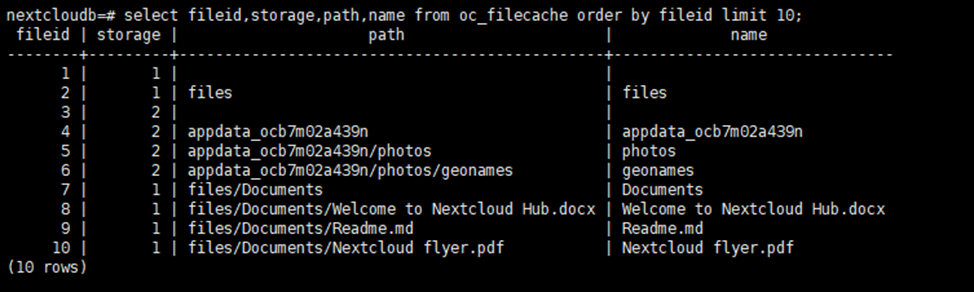
Все хранилища прописаны в oc_storages
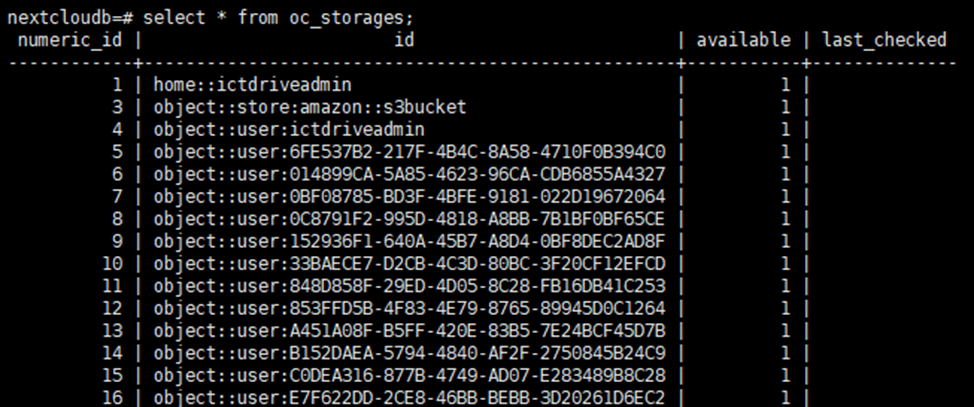
Для каждого пользователя создается отдельное хранилище.
Хранилища с префиксом home – это локальные хранилища, то есть, если все файлы хранятся на локальном диске
Хранилища с префиксом object::user – это объектные хранилища
Соответственно, файл Nextcloud flyer.pdf ссылается на хранилище 1, то есть home::ictdriveadmin и будет искать файл в директории {{datadirectory}}/ictdriveadmin/path
В случае с объектным хранилищем по-другому. Берется хранилище указанного пользователя, например object::user:A89D0551-EAEA-4AD7-925A-756564A38D7E, берется, у файла выбирается fileid, например 867, и составляется имя urn:oid:fileid, то есть urn:oid:867 и делается запрос к объектному хранилищу.
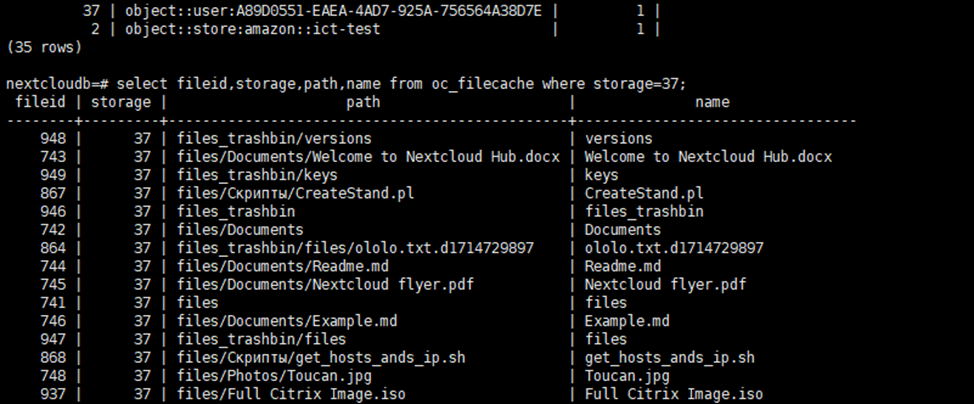
Заменяем локальные хранилища на S3. Поскольку ID storage для файлов мы изменить не можем (у них уникальный индекс на fileid и storage), то меняем название самого storage. То есть, значение home::A89D0551-EAEA-4AD7-925A-756564A38D7E поменяется на object::user:A89D0551-EAEA-4AD7-925A-756564A38D7E
Через UUID обозначены доменные пользователи, но все зависит от того, как настроена доменная аутентификация, вместо UUID может быть и логин.
Замена имен хранилищ выполняется следующим запросом
update oc_storages set id = concat('object::user:', substring(id from 7)) where id like 'home::%';Заменяем имя хранилища, которое хранит в себе метаданные.
update oc_storages set id = 'object::store:amazon::{{bucket-name}} where id like 'local::%';Настраиваем объектное хранилище в конфигурационном файле Nextcloud
Внутри массива $CONFIG добавляем объект
'objectstore' =>
array (
'class' => '\\OC\\Files\\ObjectStore\\S3',
'arguments' =>
array (
'bucket' => 'bucket-name',
'hostname' => 's3_url',
'key' => 'access_key',
'secret' => 'secret_key',
'use_path_style' => true,
),
),use_path_style нужен в тех случаях, когда объектное хранилище не от Амазона.
После этого запускаем Nginx и PHP и смотрим на результаты