Необходимые запросы:
- Вычислить размер индекса — select pg_table_size(‘indexname’);
- Список индексов в БД — SELECT indexname FROM pg_indexes WHERE schemaname = ‘public’;
- Список индексов таблицы — SELECT * FROM pg_indexes WHERE tablename = ‘tableName’;
- Состояние индекса — SELECT * FROM pgstatindex(‘indexName’);
- Загрузка большого количества данных в таблицу — INSERT INTO vac(s) SELECT ‘A’ FROM generate_series(1,500000);
- Удаление данных в произвольном порядке — DELETE FROM vac WHERE random() < 0.9;
- Количество строк в таблице — select reltuples from pg_class where relname=’ _scheduledjobs27518′;
- Количество мертвых строк в таблице — select n_dead_tup from pg_stat_all_tables where relname=’_accrg1251′;
Изменения индекса после создания таблицы и загрузки данных
Создаем таблицу vac с полем s типа int.
В ней создаем индекс по полю s.
Проверяем состояние индекса.

Как видим, столбцы avg_leaf_density и leaf_fragmentation сообщают о том, что в них записано не число. Связано с тем, что данных в таблице пока нет, о чем говорят столбцы internal_pages и leaf_pages.
После этого попробуем добавить в таблицу 500000 строк и проверим состояние индекса.
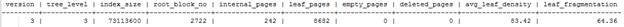
Как видим, появилась фрагментация индекса. После этого попробуем добавить еще столько же строк.

Как видим, ситуация не изменилась, поскольку данные вставились по порядку, соответственно фрагментация осталась прежней.
Вывод: добавление данных не ведет к фрагментации индекса.
А теперь попробуем удалить часть данных в произвольном порядке.

На удивление, ничего не изменилось. Связано это с тем, что удаленные строки фактически в таблице еще присутствуют, но уже как мертвые.
Проверим этот факт.
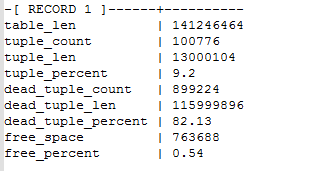
Как видим, процент мертвых строк составляет 82% и при этом свободного пространства только 0.54%.
Избавимся от мертвых строк, запустив обновление статистики и проверим таблицу еще раз.
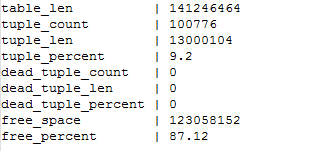
Как видим, мертвых строк более нет и процент свободного пространства увеличился. Данное пространство будет использоваться под другие данные, но если из таблицы было удалено большое количество строк и необходимо освободить место, то необходимо выполнить vacuum full, что освободит пространство на жестком диске.
Теперь посмотрим, что представляет из себя индекс

Как видим, фрагментация такая же, но листовое заполнение сильно упало, что приведет к неоптимальному поиску по индексу.
Выполним реиндексацию индекса и посмотрим на результаты.
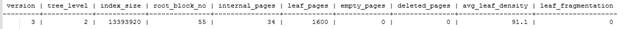
Листовое заполнение увеличилось и фрагментация стала нулевой.
Вывод: Если таблица активно используется и на добавление и на удаление, то в процессе появляется большое количество мертвых строк, а также снижается процент заполнения индекса. Для исправления данной ситуации необходимо сначала проводить обновление статистики, а затем проводить реиндексацию.
Если на базе не включен автовакуум или включен, но не настроен, то таблицы могут начать расти в размерах. Поэтому надо или проводить вручную или по расписанию вакуум таблиц или же настраивать автовакуум.
Как понять, что таблица требует очистки.
Вычисляется по следующей формуле:
Количество строк в таблице * autovacuum_vacuum_scale_factor + autovacuum_vacuum_threshold > количество мертвых строк.
Если результат вычисления больше количества мертвых строк, то таблица нуждается в очистке.
Допустим, autovacuum_vacuum_scale_factor у нас 0.01, а autovacuum_vacuum_threshold равен 50.
Тогда запрос, показывающий таблицы, требующие очистки, будет следующим.
SELECT
stat.relname,
stat.n_dead_tup dead_tup,
class.reltuples * 0.01+50 max_dead_tup,
stat.last_autovacuum
FROM
pg_stat_all_tables stat,
pg_class class
WHERE
class.oid = stat.relid and stat.n_dead_tup > class.reltuples * 0.01+50
order by last_autovacuum desc;
Для понимания, что делается в этом запрос.
Из таблицы pg_stat_all_tables выбираются названия таблиц и количество мертвых строк в них, например
select relname,n_dead_tup from pg_stat_all_tables where n_dead_tup > 0 order by n_dead_tup desc limit 10;
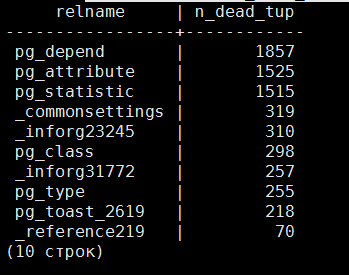
Как видим, в этих таблицах больше всего мертвых строк.
Далее, мы выбираем количество строк в таблице из представления pg_class, и умножаем на наш параметрautovacuum_vacuum_scale_factor и прибавляем к нему autovacuum_vacuum_threshold запросомselect relname, reltuples*0.01+50 dead from pg_class limit 10;
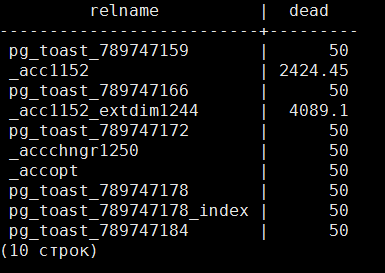
Таким образом получаем список таблиц и количество мертвых строк в них, необходимых для того, чтобы у нас запустился автовакуум. А далее, проводим сличение relid из представления pg_stat_all_tables и oid из представления pg_class, таким образом мы получим те таблицы, которые нам нужно провакуумить. В тестовой базе у нас таких нет, поскольку автовакуум там настроен. Проверим, что в рабочей базе. В рабочей база картина такая, что автовакуум возымеет действие, если установить параметр в 0.005, то есть когда будет изменено reltuples * 0.005 строк.

Как видим, только в таком случае будет проводиться автоочистка, что может вызвать повышенную нагрузку на систему. Поэтому на данный момент хватает ежедневного обновления статистики по расписанию.
Помимо автовакуума также еще есть сбор статистики для планировщика, определяется параметрами autovacuum_analyze_scale_factor и autovacuum_analyze_threshold.
Для определения, нуждается ли таблица в обновлении статистики используется почти такая же формула, как и для необходимости очистки.
Количество строк в таблице * autovacuum_analyze_scale_factor + autovacuum_analyze_threshold > количество измененных строк с момента последнего обновления статистики.
Если результат вычисления больше количества измененных строк, то таблица нуждается в очистке.
Допустим, autovacuum_analyze_scale_factor у нас 0.005, а autovacuum_analyze_threshold равен 50.
Тогда запрос таков
SELECT
stat.relname,
stat.n_mod_since_analyze mod_tup,
class.reltuples * 0.005+50 max_dead_tup,
stat.last_autoanalyze
FROM
pg_stat_all_tables stat,
pg_class class
WHERE
class.oid = stat.relid and stat.n_mod_since_analyze > class.reltuples * 0.005+50
order by stat.last_autoanalyze;
В тестовой зоне также настроен автообновление статистики, поэтому данный запрос там выдает вот такие результаты. Toast-таблицы не анализируются, поэтому попадают в запрос.
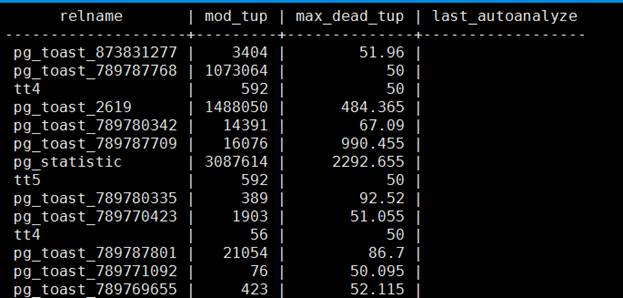
Попробуем выполнить в рабочем контуре, где настройки другие
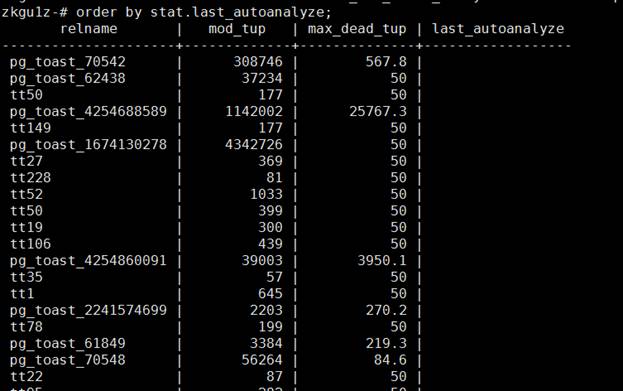
Там такая же картина. Не является ли это некорректной настройкой. Проверим, как много измененных строк появилось в таблицах после последнего обновления статистики. Для анализа возьмем первые 10 строк.
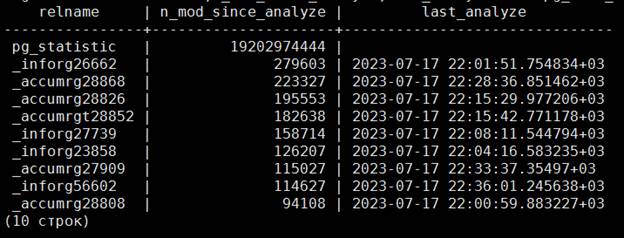
Как видим, с момента последнего обновления статистики, а оно было 17 июля 2023 года в 22:01 (Я пишу эти строки в 18:16 18 июля 2023 года, то есть спустя 20 часов), в таблице изменилось 279603 строки. Много это или мало? Посмотрим, сколько строк в таблице _inforg26662.
select reltuples from pg_class where relname=’_inforg26662′;

В переводе на человеческий означает 20789700 строк в таблице. При нынешних настройках, чтобы выполнялось автоматическое обновление статистики, должно быть изменено 2079020 строк, а у нас изменилось только 279603 строки. Для автоматического обновления должно быть значение autovacuum_analyze_scale_factor равным 0,001, тогда обновление статистики будет автоматическим. Другой вопрос, надо ли. На данный момент вполне хватает обновления по расписанию и скорость работы нареканий не вызывает, поэтому автоматическое обновление статистики оставить на будущее.
Индексы
Один из самых тяжелых индексов хранится в таблице субконто _accrged1297. В ней три индекса размерами 15 Гб, 9 Гб и 19 Гб.
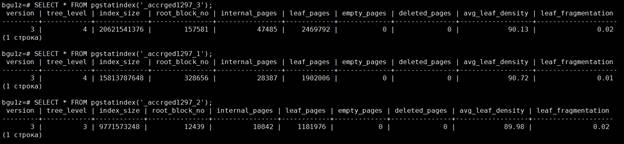
На данный момент листовое заполнение достаточно высокое, фрагментация низкая, поскольку по вечерам проводится реиндексация.